Duo Voice
Overview
I've been working at amplemarket for 2 years, and we've already solved the outbound game for Linkedin actions, and for text (both Linkedin Messages and email messages). This leaves us with two unexplored channels: voice and video. Duo Voice is our first step into the voice space.
Duo Voice, as the name suggests, solves the voice messages problem. It allows to bulk generate voice messages for Linkedin, with a human-like voice, and a natural tone.
Why?
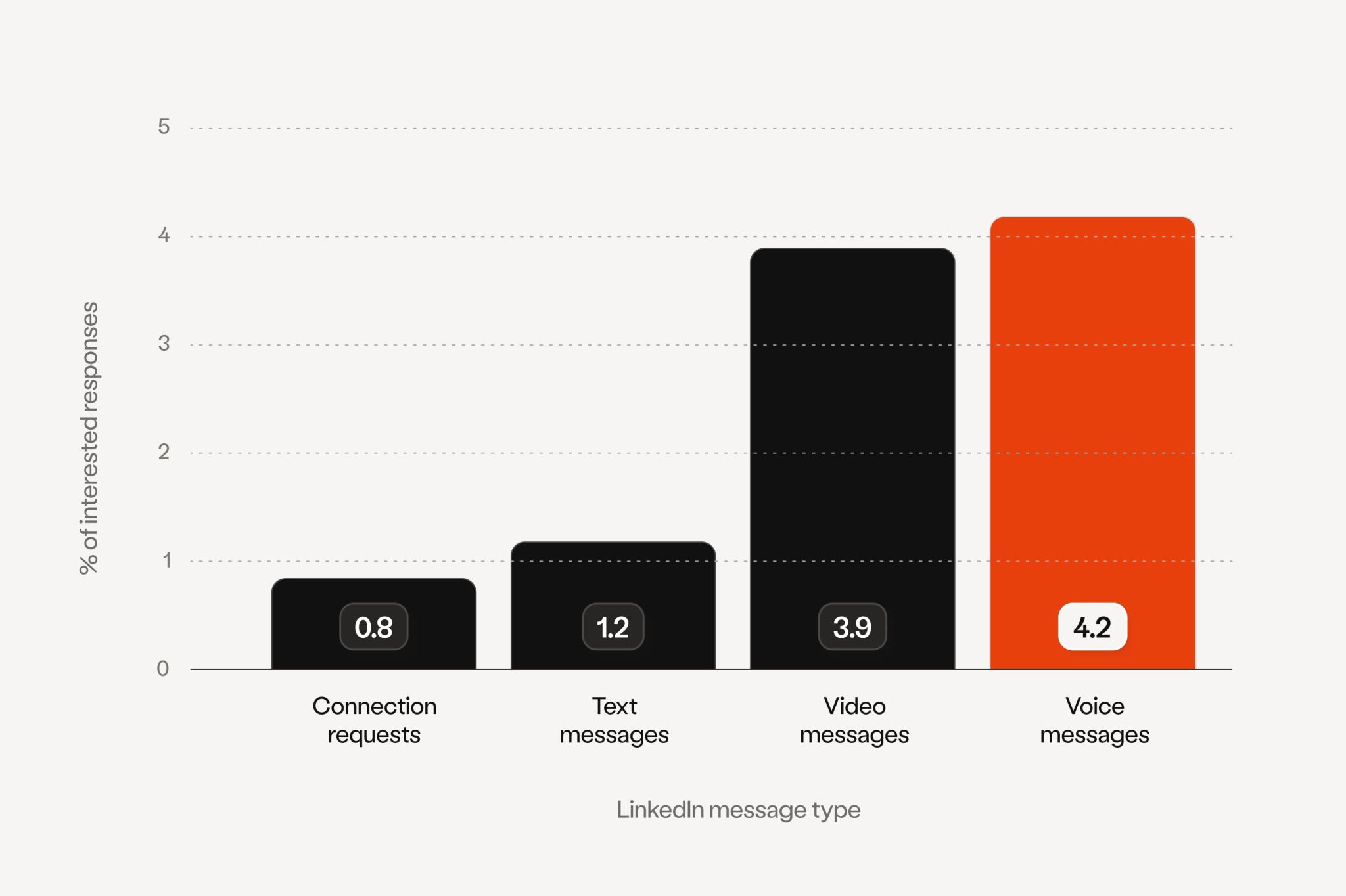
Everyone is doing the same, send emails and linkedin messages. The problem is that everyone is doing it, so it's hard to stand out. Voice messages are a great differentiator. I mean, if you had received a voice message from a sales rep, would you reply to it? I know I would, and data really shows it.
How much? Well, 200% higher response rates with your voice.
Our data shows that personalized voice messages drastically increase reply rates compared to traditional outreach methods. When prospects hear an actual human voice speaking directly to them, they're much more likely to engage. It's harder to ignore a voice than a templated message that looks like every other sales email in their inbox.
The problem is that it's hard to actually take the time and record dozens of voice messages a day. So, we basically thought: what if we could clone someone's voice, make it sound super natural, and generate a bunch of messages out of it?
Architecture

What started as a voice cloning project evolved into a sophisticated distributed system with multiple specialized services. The technical complexity required breaking down the problem into several interconnected components:
- Text-to-Speech (TTS) Service - A multi-provider system integrating ElevenLabs and PlayHT, with intelligent fallback and load balancing. Each provider is wrapped in its own service layer, allowing us to leverage their unique strengths while maintaining consistent quality.
- Audio Transformation Service - includes speed adjustments, background noise calibration with SNR (Signal-to-Noise Ratio) control, and format conversions between MP3, MP4, OGG, and WAV.
- Script Generation Service - uses gemini to transform formal written text into natural speech patterns, adding appropriate pauses, emphasis, and conversational markers.
- Language Detection & Processing - just a simple LLM voice detection service to detect the language of the voice sample and inform the TTS service of the best provider to use.
Quality & Validation
A final part of the system is the quality and validation service. We basically want to monitor the quality of the generated voice messages, and make sure there are no hallucinations in the audio. There are two main parts to this:
- Audio Metrics Service - Real-time analysis of audio quality, measuring factors like clarity, background noise levels, and speech naturalness.
- Validation Pipeline - Automated quality checks ensuring generated messages meet our standards before delivery. We are basically looking to detect hallucinations in the audios, such as long breaks, stupid words, and other stuff that doesn't sound right. This is mostly just VAD, but we also match transcriptions with the original script to detect if the TTS is saying something different.
This architecture allows us to process thousands of voice messages daily while maintaining high quality and natural-sounding output. The system's modularity means we can easily add new providers or features without disrupting existing functionality.
The major problems
- Creating a text processing pipeline that handles everything from language detection to emotion markers - gemini turned out to be a great help here.
- Building a speech generation system that doesn't just read text, but actually understands punctuation and context - play.ht and eleven labs were our best friends here.
- Finding the perfect level of background noise - too clean sounds artificial, too noisy sounds unprofessional - we developed a calibration system that adds just enough ambient sound to make messages feel authentic without compromising quality.
- Enabling multilanguage voice cloning for users who record samples in one language but need to speak in another - like cloning your Portuguese voice to speak fluent German messages.
- Handling non-native accents in voice cloning - ensuring that sales reps with accents could still generate natural-sounding messages that maintain their unique vocal identity while being clear and professional.
- Implementing robust security measures to prevent voice clone misuse - we've built verification systems that ensure only authorized users can create and send messages with their voice, preventing potential scams or impersonation attempts.
- Making sure the whole thing scales - because when you're sending thousands of voice messages, every millisecond counts - we've moved from a manual validation process to an automatic one.
The Results
It's been a long journey, but the results have been pretty incredible. And it really is amazing seeing not only the impact over reply rates, but also that people can't tell the difference between a generated and a real voice message.
Well, this wasn't easy, we had to build trust with our users, because turns out that people are really protective of their voice (even though they are reaching out to strangers, who clearly don't know how they actually sound).
The funniest is that we started with a beta that required manual approval and validation of the generated voice messages, and we've rapidly learned that we needed to make it easier to use.
So, as we proved the quality of the generated voice messages, we've moved to a system that automatically generates and sends the LinkedIn voice messages.
And that's it! If you want to learn more about Duo Voice, you can check the product page and the launch post below.
Check below for the product page and launch post: